Belated highlights from RecSys 2021
From Scene of Amsterdam (19th century) by Charles Euphrasie Kuwasseg, via Dorotheum.
In September, I virtually attended ACM’s RecSys conference, which was held in Amsterdam this year. I watched nearly 70 talks, ranging from keynotes to quick poster sessions, and below I’ve collected thoughts on some of the talks that I most enjoyed. I’ll also come back and add links to the talk videos once they’ve been posted.
For those unfamiliar, RecSys focuses on all things related to recommender systems: models which (roughly speaking) predict what items a user will like. Not only are recommenders what I’ve been working on for the last couple of years, but it’s also a topic I find personally fascinating, and I hope you will too.
P.S. Some other folks also published their highlights of the conference. Check out Eugene Yan’s “Papers and Talks to Chew on”, Vicki Boykis’ RecSys 2021 Recap, Balázs Hidasi’s Impressions and Summary for more.
Practical issues
These talks focus on issues surrounding recommender systems in production and, as a result, come largely from industry.

Twee jongens en een ezel (20th century) by Julie de Geluk, via the Rijksmuseum.
Jointly optimize capacity, latency, and engagement in large-scale recommendation systems
Presented by Hitesh Khandelwal from Facebook. Paper at ACM and Facebook Research.
Facebook has been in the news a lot lately for failing to prevent harms caused by their platform, even when their research shows that those harms are real. A user’s experience with Facebook (and Instagram) is heavily mediated through their interaction with a number of different recommender systems, which makes Facebook’s present situation an important case study for anyone interested in ethical issues surrounding recommender systems.
Facebook did give a talk on mitigating long-term effects of recommenders during the conference (they concluded that even weak preferences for borderline content would inevitably be amplified and that the best you can do is try to slow this process down) but that’s not paper I want to talk about.
This particular paper focuses on scale, something Facebook knows better than almost anyone. In particular, how can recommendation models behind Facebook Marketplace be optimized to perform well for their first-order task (presumably engagement, conversion, etc.) while reducing latency and the computational cost of serving over one billion users per month?
- The first step of the solution is the obvious one: cache recommendations from the “sophisticated and computationally expensive” ranking model to save on CPU cycles and latency that would result from online inference.
- The world and the user are always changing, so a lighter-weight “adjuster model” corrects for changes in user and item features since cache time. The adjuster model is distilled from the full ranker but takes into consideration a) the latest features, b) the “gap time” between caching and the present, and c) deltas in important features between caching time and present.
- Lastly, pre-fetch recommendations to device upon opening the Facebook app (but before navigating to the Marketplace pane). In particular, results are only pre-fetched if indicated by the results of two more models: one which estimates the probability of opening marketplace, and another model which estimates latency of generating the rankings.
All in all, it’s eye-opening to see the amount of engineering that goes into delivering computationally-intensive recommendations at massive scale.
Recommendations at a reasonable scale in a (mostly) serverless and open stack
Presented by Jacopo Tagliabue from Coveo Labs. Paper and video at ACM, code on Github, a similar talk from the same author on YouTube, and a similar blog post from the same author on Towards Data Science.
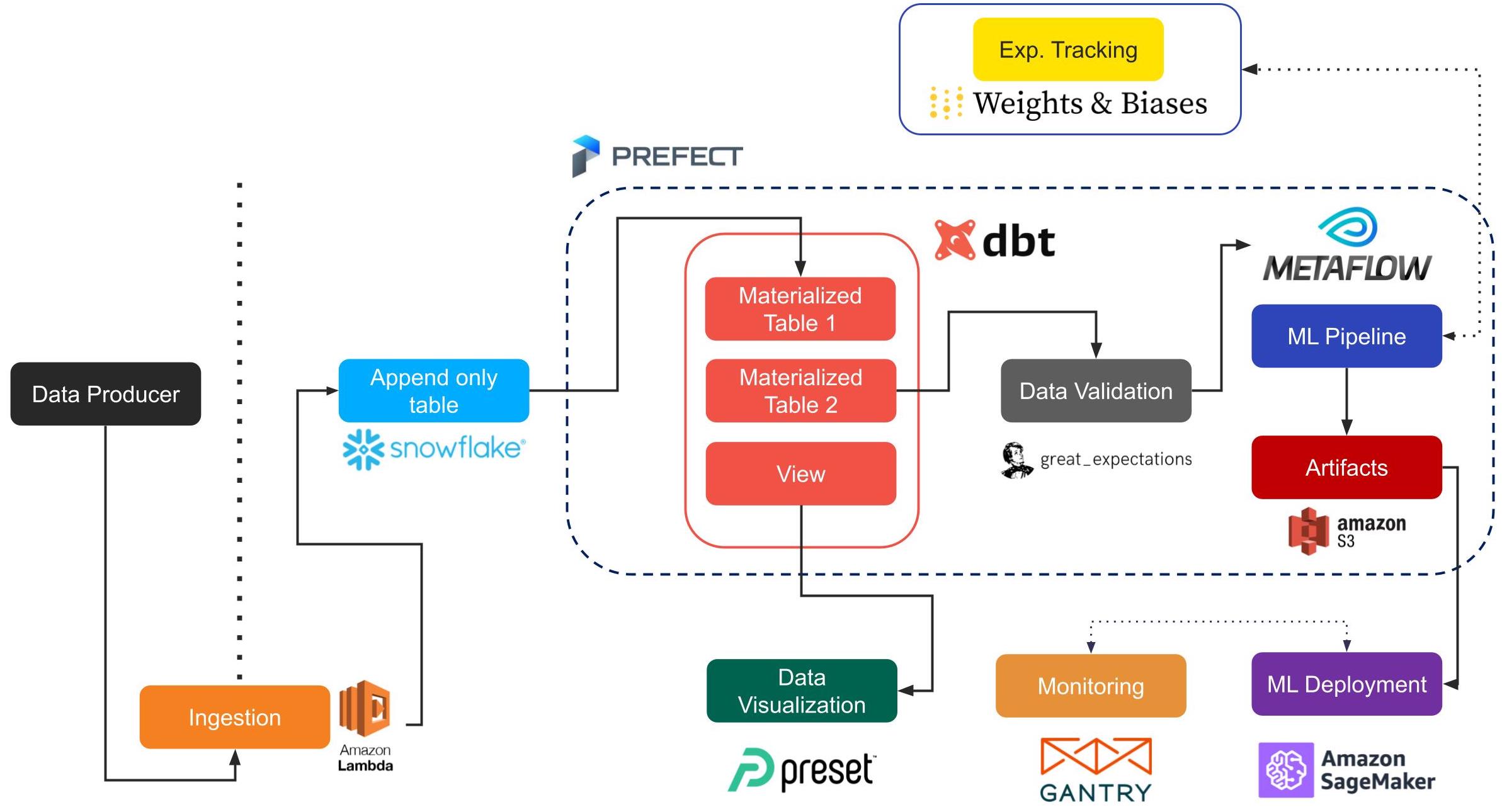
We just saw how much technical muscle Facebook throws at their scale issues, but the chances are that you’re not Facebook, and you don’t need solutions which scale to billions of users.
Tagliabue defines “reasonable scale” as companies with a finite commodity cloud budget, dozens (not hundreds) of engineers, making 9 (not 10) figures per year, with terabyte (not petabyte) scale data. If this sounds like you, then the talk’s accompanying repo offers an architecture for a non-trivial recommender system, including data validation, deployment, monitoring, and orchestration, using open-source tools like dbt, Metaflow, and so on.
Regardless of whether you intend to use any of the architecture, Tagliabue’s principles are valuable. He stresses the importance of data quality and leveraging the many high-quality SaaS/PaaS offerings so you can avoid time-consuming infrastructure maintenance.
RecSysOps: Best practices for operating a large-scale recommender system
Presented by Ehsan Saberian from Netflix. Find the paper at ACM and a video of the talk on YouTube.
This talk was one of a few that stressed the importance of having a good ops backbone when building and maintaining recommender systems. “RecSysOps” is broken into issue detection, prediction, diagnosis, and resolution, all of which are easier said than done.
I particularly liked that a team could take on these suggestions in an iterative approach. For starters, implement best practices and end-to-end monitoring, with a focus on the types of issues that are important to your stakeholders. Once issue detection is (relatively) under control, you might try your hand at predicting future issues.
My favorite piece of advice was: “with every issue, make your RecSysOps better.” In other words, if detection was hard for this type of issue, try to predict it in the future. If resolution was hard, build a tool to automate the solution in the future.
Three talks on organizational issues
If “RecSysOps” is about the software practices which support recommender systems, these two talks are about the communication and cultural practices which support doing data science in a large organization:
- Scaling enterprise recommender systems for decentralization by Maurits van der Goes, Heineken. The “decentralization” in this case is not about distributed systems or cloud architectures, it’s about decentralized organizations and how to build valuable ML infrastructure for a large company with heterogenous needs.
- Challenges experienced in public service media recommendation systems, presented by Andreas Grün for ZDF. Grün discusses the need to meet different teams within the organization where they were, exposing the appropriate abstractions and levels of control. He also brought up a topic rarely addressed at the conference: reducing energy consumption by (for example) replacing deep sequential recommenders with heuristics.
- Building public service recommenders, presented by Christina Boididou for the BBC. Another great talk about recommenders in the public service sector, with insight on the organizational, infrastructural, and cultural challenges of brinigng recommendations to a 99-year-old organization which previously relied on editorial curation.
Algorithmic advances
These talks are focused more on new ideas, methods, and algorithms, as well as new perspectives on issues related to recommender systems.

Roeiboot op zee (19th century) by Frans Arnold Breuhaus de Groot, via the Rijksmuseum.
Top-k contextual bandits with equity of exposure
Presented by Oliver Jeunen for University of Antwerp. Paper at ACM and the author’s website, code on Github.
Olivier Jeunen and Bart Goethals won the Best Student Paper award for their other RecSys paper Pessimistic reward models for off-policy learning in recommendation, but I particularly liked this one on bandits with equitable exposure.
The key idea is that a small difference in the computed relevance between two items might mean a big difference in exposure if one item gets knocked out of the top k items shown in a module. You may have any number of reasons for wanting to ensure equitable exposure among your item population, which makes this a potential issue.
The paper’s exposure-aware arm selection (EARS) algorithm attempts to ensure that a probability of an item being clicked is proportional to its relevance and not unduly confounded by extraneous exposure effects. The math gets a bit above my pay-grade, but the experimental results on Deezer’s carousel dataset suggested that EARS improves equitable exposure with minimal impacts to expected reward. There’s even a hyperparameter to control the fairness-reward trade-off.
Cold start similar artists ranking with gravity-inspired graph autoencoders
Presented by Guillaume Salha-Galven from Deezer. Paper at ACM and Arxiv.
This paper tackles the task of generating a “similar artists” module for new artists on Deezer, who have metadata but few streams.
The authors formulate the problem as a weighted, directed graph of top-k similar artists, and they want to predict edges linking to the cold-start nodes. A graph autoencoder is used to learn graph embeddings from the topology of the graph and the artist features, but graph autoencoders are typically for undirected graphs, learning a metric space where d(x,y)=d(y,x) for any pair of items.
To adapt the method for their directed graph, they learn a vector and a mass for each node, where directed edges are modeled as accelerations due to “gravity” and popular artists end up having larger mass. This makes sense: the Beatles might be a top similar artist for many artists, but there’s a high bar to make it into the similar artists list for the Beatles. I thought this was a particularly intuitive and clever solution and according to the paper it beat a long list of baseline approaches.
Reverse maximum inner product search
Presented by Daichi Amagata from Osaka University. Paper at ACM and Arxiv.
Many recommender systems are variants of matrix factorization or other factorized models: you learn a vector for the user, a vector for the item, and the score for that pair is the dot-product of those vectors. We can take a user vector, multiply it by the entire item matrix, and rank the scores to get an ordered list of recommendations for that user.
But what if you’ve got a new item vector and you want to know which users would have that in their top k recommendations (to know how well a product might perform, or who to market it to)? You could generate the top recommendations for every user, but that’s expensive. This is the gist of the reverse maximum inner product search problem.
The paper proposes an algorithm for doing this quite quickly, without any approximation. I’ll leave the heavy-lifting to the paper, but the trick is to avoid computing the full top-k result set by building a data structure to support computing upper- and lower-bounds on the kth largest inner product for a user. The end result is miles faster than any other exact solution…mostly because the alternatives all involve solving the (forward) maximum inner product search problem for every user.
Given the prevalence of factorized models for recommendation, this seems like a very promising tool to have.
Transformers4Rec
Presented by Gabriel de Souza Pereira Moreira from NVIDIA, with co-authors from NVIDIA and Facebook. Paper at ACM and Facebook Research, with a blog post on Medium and code on Github.
I am not an expert in NLP and I will not attempt to explain attention and transformers to you (though here’s a good walkthrough if you want one). If you’ve heard folks talking about the incredible things that BERT and GPT-3 can do, well the T in those names stands for transformers.
Transformers operate on sequential data, which is a natural fit for language (i.e. sequences of words), but has now been adapted for sequential recommendation contexts: given a sequence of user-item interactions, predict the next item that the user will interact with. Since transformers have quickly become the de facto backbone of the latest state of the art in language models, we shouldn’t be surprised to find that this paper boasts wins in the WSDM and SIGIR recommendation challenges.
Given the model performance, the pedigree of the NVIDIA and Facebook, and the fact that they offer Tensorflow and PyTorch implementations, I suspect that we’ll be seeing a lot of Transformers4Rec in new sequential recommenders and various deep learning architectures for recommendation.
Two talks on theory
Two of my favorite talks were both presented by Minmin Chen, from the Google Brain team.
- The first talk creates a foundational framework for discussing exploration in recommender systems (which is also the name of the paper). Chen breaks this down into system exploration (surfacing tail content content to benefit content providers and to improve the model), user exploration (discovering serendipitous content for users), and online exploration (reducing model uncertainty on rarely seen items without hurting the user), and she offers ideas on how to measure each of these facets.
- The second talk, Values of user exploration in recommender systems, elaborates on the user exploration facet. The authors performed offline and online tests on several REINFORCE-based models which emphasize exploration and measured results for accuracy, diversity, novelty, and serendipity. The paper does a great job building on the principles laid out in the previous paper and putting them to work by demonstrating value on real users.
Other talks of note
At the risk of outlining every single talk from the conference, below I list just a few more talks that all deserve a look for one reason or another.

- Explainable attribute-aware item-set recommendations from Yang Li et al at Amazon. This paper shows off a model which generates a module of similar recommended items alongside relevant attributes that the user might want to compare between them (see image above). It’s one thing to hand-pick the attributes to show if you’re a small retailer with only a few types of goods, but Amazon needs a solution that can adapt to basically any type of product. Also available from Amazon.
- Recommendation on live-streaming platforms: Dynamic availability and repeat consumption from Jérémie Rappaz and his colleagues at EPFL and UC San Diego. Live-streaming platforms like Twitch are becoming one of the largest sources of video content, and this paper discusses some of the unique challenges they pose for recommendation. In particular, recommenders must learn to recommend intelligently among the streamers currently broadcasting and understand dependencies between them. Also on the author’s website.
- I’ve seen a lot of talk about Negative interactions for improved collaborative filtering: Don’t go deeper, go higher from Harold Steck and Dawen Liang from Netflix. The paper contributes to the ongoing conversation around the extent to which deep learning has been or will be useful for recommendation (as did another paper this year). I don’t have a horse in that race, but I found the choice of model inputs (using a user’s previous items and item pairs as inputs) clever, and I particularly like the fact that they focused on inputs that led to negative scores—learning these types of anti-recommendations is often difficult for many traditional models.
- Page-level optimization of e-commerce item recommendations from Chieh Lo et al from eBay. I mostly like this paper because it focuses on an atypical recommendation setting: personalizing the modules on an item display page. The page is even modeled as a sequence of modules with an RNN. The paper’s got offline and online experiments, a detailed end-to-end architecture, and real-world results: 2.48% increase in click-through and 7.34% increase in purchase-through. Also on Arxiv.
- Burst-induced multi-armed bandit for learning recommendation from Rodrigo Alves et al at TU Kaiserlautern. This paper adds a neat twist to the context-free multi-armed bandit by accounting for “bursty” activity (e.g. tons of searches for David Bowie after his death). The bandit has a stationary distribution it updates for ordinary activity, but switches to modeling a separate burst distribution when unusually high activity is detected.
I loved getting to hear a wide variety of perspectives on issues in recommendation and I’m looking forward to attending next year, ideally in person.