Highlights from KDD 2023

California Spring Landscape (circa 1920) by Elmer Wachtel, via the Smithsonian American Art Museum.
In August I attended ACM’s 29th Conference on Knowledge Discovery and Data Mining, better known as KDD, in Long Beach, California. Nearly three months later (whoops), my head is still overflowing with everything I saw there: I watched more than 50 paper talks, plus keynotes, invited talks, and workshops—and I still ended up missing several things I wanted to see. In this post, I’ll give an overview of what I saw and run down some of my favorite papers and talks from the conference.1
Themes and trends
There were a few themes that I came across repeatedly at the conference. The first is no surprise: everyone is talking about large language models. Google’s Ed Chi gave a keynote on “The LLM Revolution,” there was even an “LLM day”, featuring a great talk from OpenAI’s Jason Wei on new paradigms that LLMs have ushered in. That being said, I couldn’t help but notice that (with a few exceptions) the vast majority of work I saw presented was not leveraging LLMs.
Another recurring motif was scale and the issues it raises. Problems that are tractable on a small scale raise new algorithmic and engineering challenges when scaled to millions of users and items.
Lastly, I noticed that the majority of recommender papers formulated the problem as multitask. It’s no longer sufficient to optimize for click rate alone: authors acknowledge that users and businesses have multiple goals and those goals can potentially be mutually satisfied by a single model.
Recommender systems
Because my work focuses on recommender systems and personalization, I spent a disproportionate amount of time attending talks on the topic. These talks typically, though not always, come from an industry setting and are much easier for me to transplant onto concepts and problems I’m already working on.
EvalRS workshop on evaluating recommender systems
I had a blast attending the EvalRS workshop on well-rounded evaluation of recommender systems, which consisted of two keynotes, lightning talks, and a hackathon.
Luca Belli gave a keynote on Practical Considerations for Responsible RecSys, where he outlined the challenges in evaluating recommender systems for fairness (what even is it?), picking metrics, and untangling personalization and discrimination. He mentioned that he has some upcoming work on “nutrition labels” for recommenders with standardized metrics, impacts beyond discrimination, transparency requirements, and more.
I was particularly fond of one of the lightning talks: Metric@Customer N: Evaluating Metrics at a Customer Level in E-Commerce by Mayank Singh et al from Grubhub. The gist is that using a fixed “N” for metrics like precision and recall from the top N recommendations per user is likely overly simplistic, neglecting to account for the fact that users’ browsing behaviors vary, and user A might realistically only ever consider the top 5 items while user B might browse 25. They propose adapting metrics to use a user-personalized N for each user, based on that user’s median or maximum items consumed in previous sessions.
In fact, I liked this idea so much that my colleagues and I implemented it for the EvalRS hackathon, which had the broad task of contributing to the well-rounded evaluation of the target dataset.2 My team consisted of myself, my colleagues Eyan Yeung and Dev Goyal from Hinge, and Alexandra Johnson of Rubber Ducky Labs, and we managed to snag second place!3 First place went to the team from GrubHub, who made several contributions including implementing metrics@N.

Jacopo holding court at the EvalRS workshop, via Mattia Pavoni.
Joey Robinson wrapped up the workshop with the second keynote, Ask and Answer: A Case Study in ML Evaluation at Snap. I really liked his central thesis, which is that a model evaluation framework has to be able to mode than just tell us “is this model good or bad?”—it has to provide a means for us to ask and answer questions about how model’s behavior.
I want to give a huge thank you to the EvalRS organizers for putting together a great workshop (and afterparty), with an extra special thanks to Jacopo Tagliabue, who’s always been generous with his time and insights on all things RecSys and ML.
Joint Optimization of Ranking and Calibration with Contextualized Hybrid Model
Xiang-Rong Sheng et al, Alibaba. Paper at ACM and arXiv.
Many recommender systems have moved from estimating user ratings or click probabilities to focusing on learning relative rankings between items, since a ranked list is often the user-facing output of the system. However, a well-calibrated estimate of click-through rate is often still desirable (especially in online advertising contexts), and ranking loss functions (which typically pass logits for each item through a softmax to measure relative importance) aren’t well-suited to well-calibrated point estimates of probabilities. The authors of this work want to have their ranking performance cake and eat their click rate estimates too.
The go-to solution for tasks with competing loss functions is to just optimize for some weighted sum of the two losses, but the authors note that it’s been done and still fails to produce interpretable probabilities. Their solution is a bit more complex, but also clever. Rather than producing one logit per item, they produce two: one representing a click and one representing a non-click. The probability estimate is the sigmoid of the difference between the click and non-click logits (equivalent to the softmax of the two logits) and its calibration is optimized with log loss. Simultaneously, the ranking performance is optimized with contrastive loss encouraging a high logit for the positive sample and a log logit for the negative samples within a session (and there may be multiple sessions within a batch). The final loss function is a convex sum of these two.
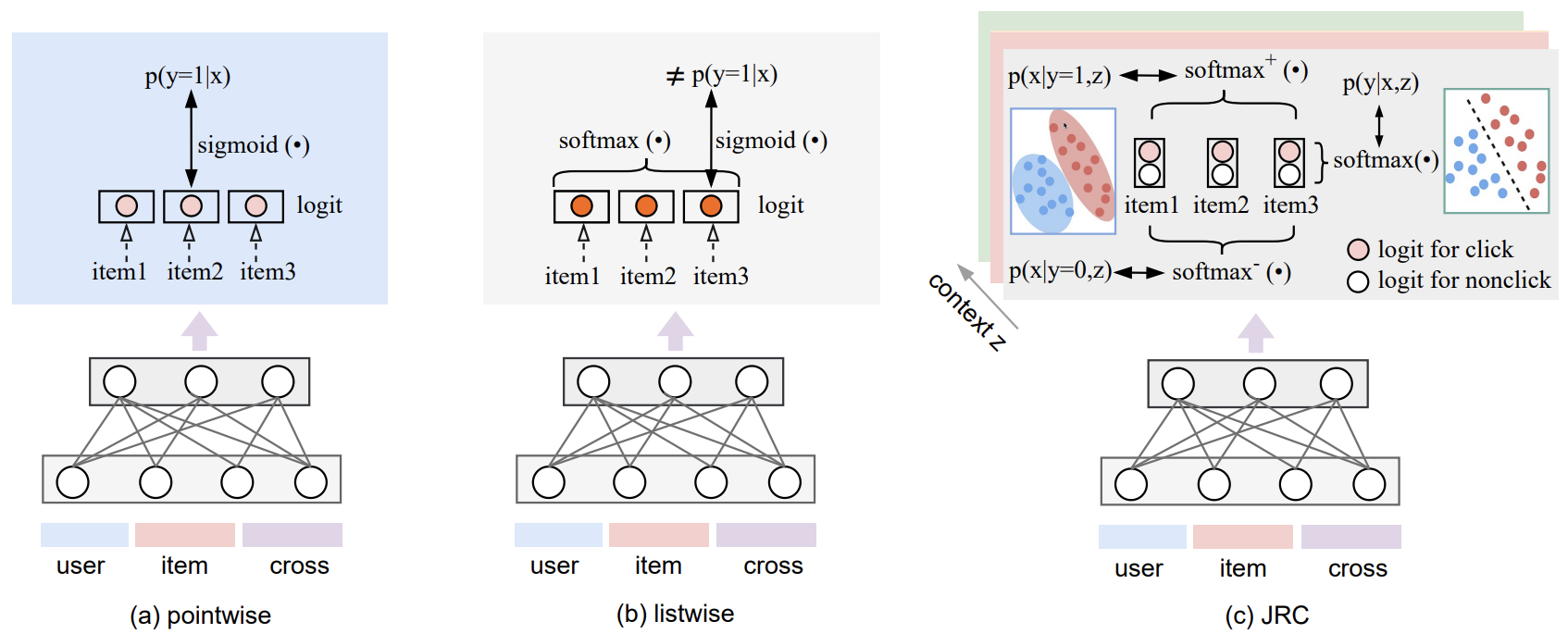
A figure from the paper comparing pointwise loss, listwise loss, and the joint ranking and calibration loss.
It’s a nice trick, and separating out negative examples by session within the batch is something I hadn’t seen before (and required some work to ensure that entire sessions would be placed together in a batch during distributed training). The authors evaluated it against pointwise, pair/listwise, and convex sum losses on two open source datasets and their own logged data from production and found it (typically) outperformed the baselines on both ranking and calibration metrics. More importantly, the model was evaluated in a user-level A/B test against a pointwise baseline and brought a 4.4% lift in CTR, 2.4% increase in revenue per thousand impressions, and a 0.27% drop in log loss.
Recommender quick hits
- Impatient Bandits: Optimizing Recommendations for the Long-Term Without Delay by Thomas McDonald et al, Spotify and University of Manchester. When recommending podcasts, Spotify found it was more valuable to model long-term engagement outcomes over short-term ones and developed a model for just that purpose. However, collecting data on long-term success of podcasts doesn’t work when you want to recommend new content. This work adapts the task of recommending podcasts for long-term engagement to the cold-start bandit setting. Using a short-term engagement proxy is not sufficient, but a continuously updated estimate of long-term engagement helps the bandit converge speedily on long-term optimal recommendations. Code available on Github.
- Controllable Multi-Objective Re-ranking with Policy Hypernetworks by Sirui Chen et al, Renmin University and Alibaba (code on Github). One of many papers on multi-task recommendation, this one aims to improve on the fact that a weighting of different objectives is often chosen during or before training time and cannot easily be changed without re-training. Their contribution is a re-ranking model which leverages a hypernetwork that can adapt the model to a new set of objective weights on the fly, allowing the same model to be used across multiple surfaces where it may have slightly different use-cases.
- Fresh Content Needs More Attention: Multi-funnel Fresh Content Recommendation by Jianling Wang et al, Google. At the core of this paper is a fairly obvious take-away for recommendation UX: it’s beneficial to set aside a slot to surface new content in order to learn more about it. However, there are modeling and engineering insights here as well, like omitting item ID embeddings from a network in order to encourage better generalization and avoid cold start problems, and designing a “user corpus co-diverted experiment” which splits both users and items in order to prevent leakage between treatment groups.
- Text is All You Need: Learning Language Representations for Sequential Recommendation by Jiacheng Li et al, UCSD and Amazon. This work presents Recformer, a sequential recommender model which encodes items as textual descriptions based on their metadata. The work doesn’t explicitly leverage the brand-name foundation LLMs we all love to talk about these days (though there are people doing that work) and instead adapts a bidirectional transformer architecture not unlike that of Longformer. The authors talk about how recommenders which rely on embeddings of item IDs lose the ability to generalize or transfer since representations linked to IDs can’t easily be shared from item to item, but I am skeptical that we need to entirely abandon item IDs.
- RankFormer: Listwise Learning-to-Rank using Listwide Labels by Maarten Buyl et al, Amazon. Read that title slowly: we’re talking about list-wise loss (measurements of ranking that consider every element in the ranked list) and list-wide signal (a label indicating whether the user received value from the entire list of recommendations). The former has existed for a while as an extension of pairwise loss functions for ranking, but the notion of listwide signal is fairly novel and comes into play particularly in cases where the user didn’t click any items in a list. Existing ranking metrics cannot learn from the case where a user doesn’t interact with any of the returned results, but the authors argue that this situation is both very frequent and a valuable source of user data. Thus the incorporation of this listwide signal allows them to augment more traditional LTR methods—indeed, their best performance was with a blend of listwise and listwide loss, rather than just one or the other.
Search
Search is intrinsically tied to recommendation and increasingly personalization, so I’ve been taking more and more of an interest in the topic.4 As large language models have blown up, search has seen a surge of interest, with particular focus on semantic search methods (which operate on embeddings rather than on text itself) and hybrid methods for tying semantic and more “classical” approaches.
Optimizing Airbnb Search Journey with Multi-task Learning
Chun How Tan et al, Airbnb. Paper at ACM and arXiv.
Just like in the Spotify Impatient Bandits paper mentioned above, Airbnb deals with optimizing outcomes with substantial delays between user actions and measured rewards—in this case, search journeys which may take weeks before a final reservation is made. Their method, Journey Ranker, is a multi-task model that leverages intermediate milestones to improve search personalization along this journey.
Airbnb searchers often abandon search sessions before ultimately making reservations later down the line, so clicks on search results are really only the first of many steps that must occur before an actual booking. Journey Ranker considers not only clicks but payment page visits, booking requests, host acceptance of booking request, and whether or not either the host or booker cancels the booking.
A shared representation embeds both the listing and search context, while the “base module” leverages this representation to make several intermediate probability estimates (probability of click given impression, booking given click, etc.) whose product is the final desired probability, as inspired by the Entire Space Multi-Task Model approach. A “Twiddler” module scores listings based on negative milestones like cancellation or booking rejection, using the same shared representation. Lastly, a combination module produces a learned linear combination the base and Twiddler module outputs.
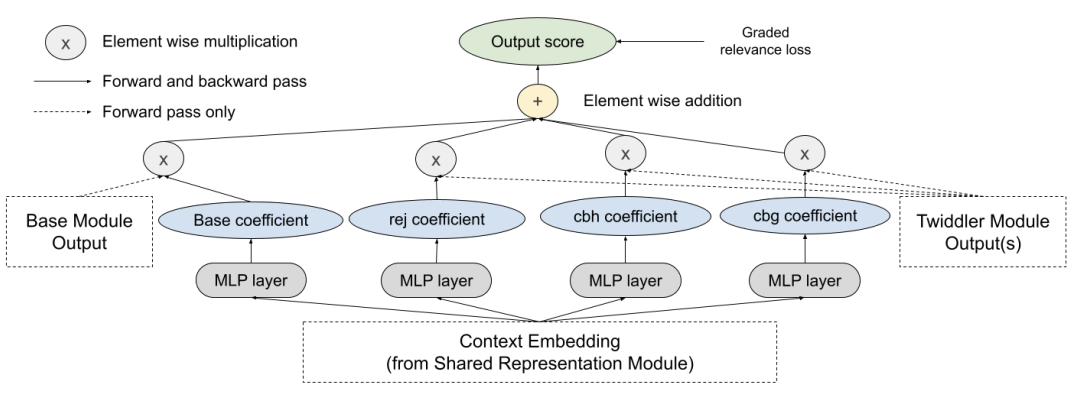
A figure from the paper visualizing the Journey Ranker combination module.
The paper goes into detail on design decisions taken and not taken, and demonstrates the interpretability of the combination module’s linear task weights. They evaluated the method in offline and online settings, with the online test leading to a 0.61% increase in uncancelled bookers. They also applied the same method to other Airbnb use cases, netting a 9.0% increase in uncancelled bookers for online experiences (a newer and less optimized flow) and a 3.7% reduction in email unsubscribes.
End-to-End Query Term Weighting
Karan Samel et al, Google. Paper at ACM and Google Research
As sexy as “semantic search” may be, deep learning models are expensive to run at massive scale. As a result, bag-of-words and n-gram methods are often still deployed, with tokens weighted by scoring functions like BM25, which has proven to be a formidable baseline.
The authors of this paper wanted to adapt newer deep learning methods to operate within the bounds of a bag-of-words system by using a language model to learn weights (end-to-end) for query terms that are used as part of the input to the BM25 scoring function.
A masked language modeling task is used for pre-training an open source BERT checkpoint. Then a second pre-training task is used to learn uniform term weights as a starting point for the actual term weighting tasks. The fine-tuning is the end-to-end step which leverages the entire information retrieval pipeline: the query is fed to the BERT model to produce term weights, which are combined with document statistics as input to BM25. A combination of pointwise and ranking loss is then back-propagated all the way back to the BERT model to update the term weights.

A figure from the paper visualizing the architecture of the end-to-end weighting system.
There’s other fancy bits in here, like using a T5 model to generate soft labels for negative examples as well as a query expansion solution which weights both the original query terms as well as expanded terms. Another challenge was reconciling the wordpieces from BERT’s tokenizer with the world-level terms used by the existing system, which required additional masking and pooling.
The model performs well on the evaluation datasets, with some tough competition from SPLADE. They don’t mention any online experiments, but note that since their model only incurs a single forward pass on BERT, it’s “tractable to perform during serving.” Nonetheless, I admire the pragmatism underlying the approach. Replacing the existing retrieval system with deep learning would be a massive infrastructural change with integration costs, not to mention monetary and performance costs, but leveraging a deep learning model within the existing system can potentially get the best of both worlds.
Search quick hit
- UnifieR: A Unified Retriever for Large-Scale Retriever by Tao Shen et al, University of Technology Sydney, Microsoft, and Ohio State University. This paper was presented right after End-to-End Query Term Weighting and practically threw down the gauntlet by claiming that methods which use a non-learnable function like BM25 to combine dense and sparse representations cannot possibly provide rich enough interaction between those representations. UnifieR learns both dense and sparse representations which share global context and supports both dense and sparse retrieval, as well as a select-then-re-rank “uni-retrieval” paradigm.
Software and engineering challenges
These papers focused less on novel algorithms (though they do include some) and more on building new solutions to improve performance and resilience. Software engineering is a fairly rare topic at ML conferences, but when it does come up it often provides a unique look behind the curtain at engineering challenges faced by some of the biggest tech companies on the planet.
Yggdrasil Decision Forests
Matthieu Guillaume-Bert et al, Google and Pinecone. Paper at ACM and arXiv, code on Github.
Yggdrasil is a new decision forest library in C++ and Python (as TensorFlow Decision Forests), with support for inference in Go and JavaScript.
I have a thing for talks about new libraries, like Transformers4Rec at RecSys 2021 or TorchRec at RecSys 2022.5 But what I really loved about the Yggdrasil talk wasn’t the discussion of features (a bazillion different tree-based models, evaluation methods, distributed training, etc.) but the focus on the design principles that went into making the library:
- Simplicity of use: helpful interactions and messages at the appropriate level of abstraction, sensible defaults, clarity and transparency
- Safety of use: warnings and errors that make it hard for users to make mistakes, easily-accessible best practices
- Modularity and high-level abstraction: sufficiently complex pieces of code should be understandable independently, with well-defined interfaces between them
- Integration with other ML libraries: avoid limiting users to methods available within their chosen library, favor composability
It reminds me of Vim’s design principles, and re-affirms my belief (partially inspired by my employer) that having principles from the outset is a good way to guide decision-making during any large project.

An excerpt from the Yggdrasil paper showing the library's approach to helpful, humane errors.
As you can see in the example from the paper shown above, these principles manifest in a library that attempts to guide you to use it correctly and effectively. The authors note that machine learning systems are often at risk of running without error, while silently doing something totally wrong, so this approach is valuable in preventing some of those potentially insidious errors.
Revisiting Neural Retrieval on Accelerators
Jiaqi Zhai et al, Meta. Paper at ACM and arXiv.
Deep learning has gained popularity in recommendation, older methods like matrix factorization have proven to be a hard baseline to beat.6 But even as matrix factorization has been largely supplanted neural alternatives, it has survived in the fundamental structure of most dense retrieval models: representing similarity as the dot product of learned vectors for users (or queries) and items. By saving all the vectors to an index, retrieval can be done with approximate nearest neighbors methods which scale to massive datasets while remaining highly performant.
But dot products just aren’t good enough for Zhai et al. They write: “The relationship between users and items in real world, however, demonstrates a significant level of complexity, and may not be approximated well by dot products,” citing the fact that interaction likelihoods are often frequently much higher-rank than these low-rank approximations can model, and noting that ranking models have mostly moved forward to more complex neural architectures. Nonetheless, there haven’t yet been solid alternatives to the maximum-inner-product search formulation. The authors seek to change this, and their contribution is threefold: a “mixture of logits” similarity function designed to outperform dot products and generalize better to the long tail, a hierarchical retrieval strategy that employs GPUs and TPUs to scale this method to corpora of hundreds of millions of items, and experiments demonstrating improvements on baseline datasets and Meta production traffic.
The authors go on to discuss not only their novel similarity function but the various tricks they employ to make it run efficiently on the GPU, bringing to mind a similar blend of algorithmic and engineering wizardry in Meta’s DLRM paper.
Improving Training Stability for Multitask Ranking Models in Recommender Systems
Jiaxi Tang et al, Google and Deepmind. Paper at ACM and arXiv, code on Github.
I mentioned that scale and multitask recommenders were major themes at KDD this year, and this paper (which was the winner on the Best Paper Award for Applied Data Science) has both. This paper is all about techniques to prevent instability (loss divergence) while training a multitask recommender for YouTube.
Training failures had clearly become a major issue for the team, and they found it hard to reproduce (models didn’t always diverge, even with the same configuration), hard to detect (divergence might occur before metrics are logged), and hard to measure. Rolling back to earlier training checkpoints didn’t address the heart of the problem and wasn’t even guaranteed to work.
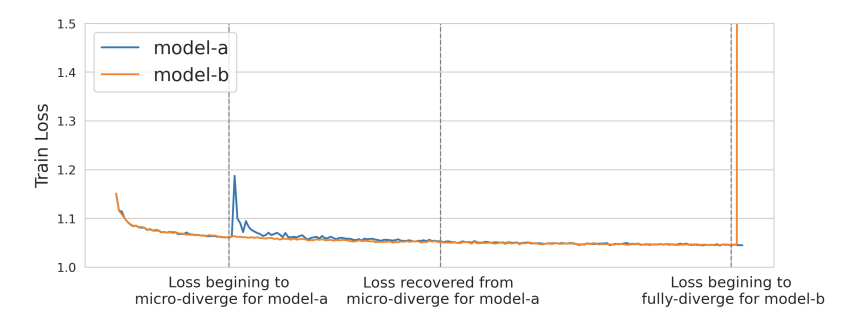
A (cropped) figure from the paper demonstrating temporary and permanent loss divergence.
They found that the root cause of loss divergence was “step size being too large when loss curvature is steep” (they even bolded it in their paper). Recommendation models are particularly susceptible because they’re trained on many features in sequential data, which means there’s a very large probability of distribution shift during training, which in turn requires a consistently large learning rate to continue adapting to these shifts. Furthermore, ranking models diverged more than retrieval models seemingly due to their larger size and their tendency to be multitask (big gradients for one task can spoil performance on others through shared layers).
The solution ends up being a fancy variant of gradient clipping, affectionately dubbed “Clippy.” What makes Clippy unique is that it controls the size of the model update rather than the size of the gradient itself—these two values are synonymous in SGD, but can be very different with more sophisticated optimizers. They also measure the size of the update using the L-infinity norm, which is sensitive to large updates in even just a few coordinates.
Engineering quick hit
- LightToken: A Task and Model-agnostic Lightweight Token Embedding Framework for Pre-trained Language Models by Haoyu Wang et al, Amazon and Purdue University. Everyone using language models likely needs to store and access a bunch of embeddings, but this can be challenging for deployment on edge devices. LightToken is a new embedding compression method which claims the state of the art in shrinking embedding tables. The four-step approach can be applied to any model backbone without the need for retraining while preserving model performance.
Grab bag
Not every paper I liked fits neatly into the themes above. Below are a few more papers of note that I wanted to highlight:
- Variance Reduction Using In-Experiment Data by Alex Deng et al, Airbnb. Variance reduction methods increase the power of controlled experiments and allow experimenters to detect smaller effects. The work is a conceptual evolution of CUPED, which leverages pre-experiment covariates for variance reduction. This paper instead uses in-experiment data, particularly leading indicator metrics which estimate the desired (but delayed) ultimate outcome. The idea is similar at a high level to the Spotify “impatient bandit” mentioned earlier: using intermediate estimates of delayed outcomes.
- Fair Multilingual Vandalism Detection System for Wikipedia by Mykola Trokhymovych et al, Wikimedia (code on Github). Wikipedia wanted to improve vandalism detection across languages, while preventing undue bias against anonymous editors who might become future repeat contributors.
- Uncertainty-Aware Probabilistic Travel Time Prediction for On-Demand Ride-Hailing at DiDi by Hao Liu et al, Didi. The authors outline how travel time prediction has evolved at the Chinese ride-hailing app, starting with gradient boosted trees, evolving to RNNs, and then to graph-based methods. But all of these techniques estimated time as a single numerical output and failed to account for potential uncertainty. Their new model estimates a travel time distribution instead, reformulating the problem as multiclass classification, where the labels are discretized bins of travel times.
- Extreme Multi-Label Classification for Ad Targeting using Factorization Machines by Martin Pavlovski et al, Yahoo and eBay. I have a big soft spot for factorization machines, a non-neural recommendation model that adds metadata features to classical collaborative filtering and which has stood as a strong baseline against (not to mention inspiration for) much fancier methods. In this work, the authors leverage a multi-label variant of FMs for ad targeting in a setting where neural methods produce an unacceptable amount of latency. Their dataset had 200,000 features, 1098 labels, and the model had only marginal memory costs versus a linear baseline, with inference in 0.16 milliseconds.
- New Paradigms in the Large Language Model Renaissance by Jason Wei, OpenAI. I’ve got to share at least one LLM talk from the conference, and my favorite was Jason’s, which discussed the ways that LLMs have led to changes in the ways ML research happens. The massive scale needed for LLMs means individual researchers can’t easily to bottom-up ideation because they need a team with specialized skills, infrastructure, and resources to test out ideas. Emergent abilities of LLMs mean that researchers constantly need new benchmarks and evaluation methods, but also mean that new use cases don’t always necessitate new models. Lastly, advances in so-called LLM “reasoning” with methods like chain-of-thought allow models to handle bigger, more complex problems which are specified in natural language.
Wrapping up
There are around 20 papers in this write-up, and I left plenty of cool talks on the cutting room floor too. I’m thankful for my employer for sending me to conferences like KDD and Recsys where I’m able to hear so many ideas and take away so much. If you think I missed a particularly cool paper or talk, or just want to share your thoughts, don’t hesitate to reach out, and thanks for reading ‘til the end! If you liked this post and want to hear more from me in the future, you can follow my RSS feed.
-
I’ll note that this selection will be pretty biased by what I chose to attend. For instance, KDD features a ton of content on graph learning, the mast majority of which I didn’t attend because I don’t do much work with graph data. On the other hand, you’ll find recommender systems and search over-represented here, as those are areas of particular interest to me. I also missed the some workshops that I would’ve loved to have seen, like Decision Intelligence and Analytics for Online Marketplaces and Online and Adaptive Recommender Systems. ↑
-
It turns out that personalizing the metric can be quite harsh: the baseline model had a hit rate at 100 of 4.8% but a hit rate at median listens/day of only 0.03%! ↑
-
Second place…though I’m not sure if more than two teams submitted 😅. ↑
-
For others interested in search basics, I’d highly recommend the Search Fundamentals course from Uplimit, taught by Grant Ingersoll and Daniel Tunkelang. It’s a great intro into key search concepts and a whirlwind tour of basic Elasticsearch/OpenSearch functionality. I took the course in February and it opened my eyes to a lot of the parallels between search and recommendation. ↑
-
I never did get around to writing that highlights of RecSys ‘22 post… ↑
-
For example, see the work of Steffen Rendle, who has contributed factorization machines and Bayesian personalized ranking to the pre-neural era of recsys. He has continued to demonstrate the performance of non-neural recommendation models several times. See also Are We Really Making Much Progress? and Reenvisioning the comparison between Neural Collaborative Filtering and Matrix Factorization. ↑